| faster_rcnn_r50_1x |
147.488 |
146.124 |
142.416 |
471.547 |
471.631 |
| faster_rcnn_r50_2x |
147.636 |
147.73 |
141.664 |
471.548 |
472.86 |
| faster_rcnn_r50_vd_1x |
146.588 |
144.767 |
141.208 |
459.357 |
457.852 |
| faster_rcnn_r50_fpn_1x |
25.11 |
24.758 |
20.744 |
59.411 |
57.585 |
| faster_rcnn_r50_fpn_2x |
25.351 |
24.505 |
20.509 |
59.594 |
57.591 |
| faster_rcnn_r50_vd_fpn_2x |
25.514 |
25.292 |
21.097 |
61.026 |
58.377 |
| faster_rcnn_r50_fpn_gn_2x |
36.959 |
36.173 |
32.356 |
101.339 |
101.212 |
| faster_rcnn_dcn_r50_fpn_1x |
28.707 |
28.162 |
27.503 |
68.154 |
67.443 |
| faster_rcnn_dcn_r50_vd_fpn_2x |
28.576 |
28.271 |
27.512 |
68.959 |
68.448 |
| faster_rcnn_r101_1x |
153.267 |
150.985 |
144.849 |
490.104 |
486.836 |
| faster_rcnn_r101_fpn_1x |
30.949 |
30.331 |
24.021 |
73.591 |
69.736 |
| faster_rcnn_r101_fpn_2x |
30.918 |
29.126 |
23.677 |
73.563 |
70.32 |
| faster_rcnn_r101_vd_fpn_1x |
31.144 |
30.202 |
23.57 |
74.767 |
70.773 |
| faster_rcnn_r101_vd_fpn_2x |
30.678 |
29.969 |
23.327 |
74.882 |
70.842 |
| faster_rcnn_x101_vd_64x4d_fpn_1x |
60.36 |
58.461 |
45.172 |
132.178 |
131.734 |
| faster_rcnn_x101_vd_64x4d_fpn_2x |
59.003 |
59.163 |
46.065 |
131.422 |
132.186 |
| faster_rcnn_dcn_r101_vd_fpn_1x |
36.862 |
37.205 |
36.539 |
93.273 |
92.616 |
| faster_rcnn_dcn_x101_vd_64x4d_fpn_1x |
78.476 |
78.335 |
77.559 |
185.976 |
185.996 |
| faster_rcnn_se154_vd_fpn_s1x |
166.282 |
90.508 |
80.738 |
304.653 |
193.234 |
| mask_rcnn_r50_1x |
160.185 |
160.4 |
160.322 |
- |
- |
| mask_rcnn_r50_2x |
159.821 |
159.527 |
160.41 |
- |
- |
| mask_rcnn_r50_fpn_1x |
95.72 |
95.719 |
92.455 |
259.8 |
258.04 |
| mask_rcnn_r50_fpn_2x |
84.545 |
83.567 |
79.269 |
227.284 |
222.975 |
| mask_rcnn_r50_vd_fpn_2x |
82.07 |
82.442 |
77.187 |
223.75 |
221.683 |
| mask_rcnn_r50_fpn_gn_2x |
94.936 |
94.611 |
91.42 |
265.468 |
263.76 |
| mask_rcnn_dcn_r50_fpn_1x |
97.828 |
97.433 |
93.76 |
256.295 |
258.056 |
| mask_rcnn_dcn_r50_vd_fpn_2x |
77.831 |
79.453 |
76.983 |
205.469 |
204.499 |
| mask_rcnn_r101_fpn_1x |
95.543 |
97.929 |
90.314 |
252.997 |
250.782 |
| mask_rcnn_r101_vd_fpn_1x |
98.046 |
97.647 |
90.272 |
261.286 |
262.108 |
| mask_rcnn_x101_vd_64x4d_fpn_1x |
115.461 |
115.756 |
102.04 |
296.066 |
293.62 |
| mask_rcnn_x101_vd_64x4d_fpn_2x |
107.144 |
107.29 |
97.275 |
267.636 |
267.577 |
| mask_rcnn_dcn_r101_vd_fpn_1x |
85.504 |
84.875 |
84.907 |
225.202 |
226.585 |
| mask_rcnn_dcn_x101_vd_64x4d_fpn_1x |
129.937 |
129.934 |
127.804 |
326.786 |
326.161 |
| mask_rcnn_se154_vd_fpn_s1x |
214.188 |
139.807 |
121.516 |
440.391 |
439.727 |
| cascade_rcnn_r50_fpn_1x |
36.866 |
36.949 |
36.637 |
101.851 |
101.912 |
| cascade_mask_rcnn_r50_fpn_1x |
110.344 |
106.412 |
100.367 |
301.703 |
297.739 |
| cascade_rcnn_dcn_r50_fpn_1x |
40.412 |
39.58 |
39.853 |
110.346 |
110.077 |
| cascade_mask_rcnn_r50_fpn_gn_2x |
170.092 |
168.758 |
163.298 |
527.998 |
529.59 |
| cascade_rcnn_dcn_r101_vd_fpn_1x |
48.414 |
48.849 |
48.701 |
134.9 |
134.846 |
| cascade_rcnn_dcn_x101_vd_64x4d_fpn_1x |
90.062 |
90.218 |
90.009 |
228.67 |
228.396 |
| retinanet_r101_fpn_1x |
55.59 |
54.636 |
48.489 |
90.394 |
83.951 |
| retinanet_r50_fpn_1x |
50.048 |
47.932 |
44.385 |
73.819 |
70.282 |
| retinanet_x101_vd_64x4d_fpn_1x |
83.329 |
83.446 |
70.76 |
145.936 |
146.168 |
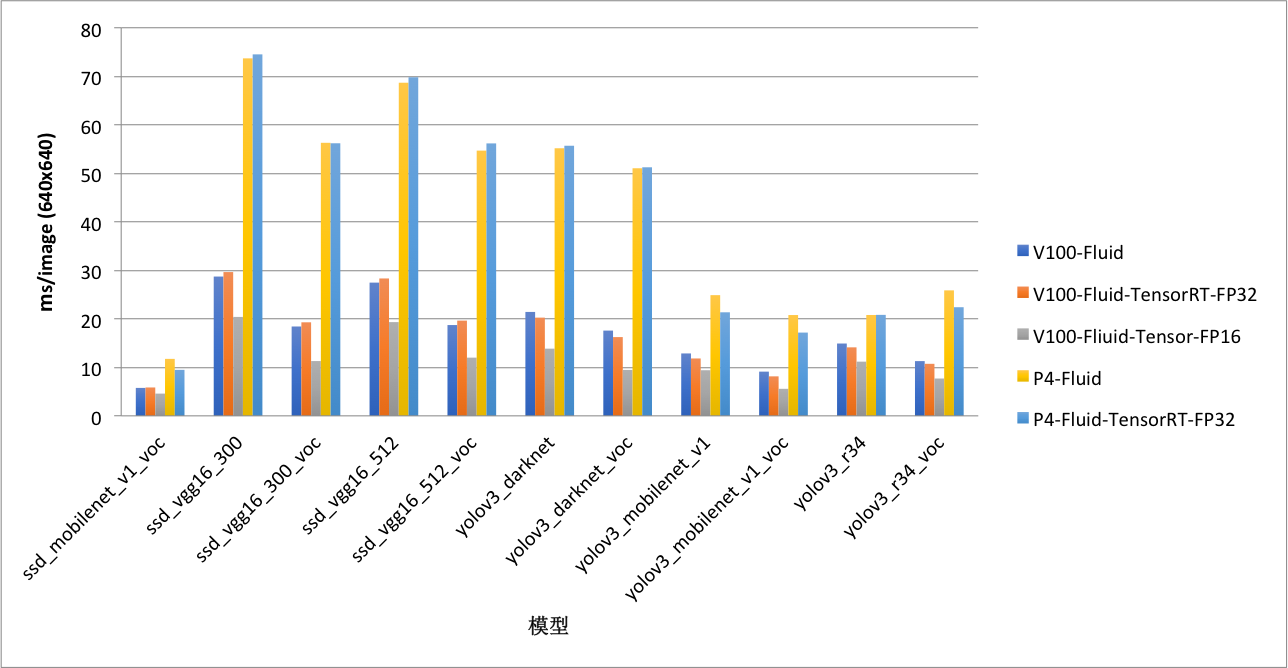
| yolov3_darknet |
21.427 |
20.252 |
13.856 |
55.173 |
55.692 |
| yolov3_darknet_voc |
17.58 |
16.241 |
9.473 |
51.049 |
51.249 |
| yolov3_mobilenet_v1 |
12.869 |
11.834 |
9.408 |
24.887 |
21.352 |
| yolov3_mobilenet_v1_voc |
9.118 |
8.146 |
5.575 |
20.787 |
17.169 |
| yolov3_r34 |
14.914 |
14.125 |
11.176 |
20.798 |
20.822 |
| yolov3_r34_voc |
11.288 |
10.73 |
7.7 |
25.874 |
22.399 |
| ssd_mobilenet_v1_voc |
5.763 |
5.854 |
4.589 |
11.75 |
9.485 |
| ssd_vgg16_300 |
28.722 |
29.644 |
20.399 |
73.707 |
74.531 |
| ssd_vgg16_300_voc |
18.425 |
19.288 |
11.298 |
56.297 |
56.201 |
| ssd_vgg16_512 |
27.471 |
28.328 |
19.328 |
68.685 |
69.808 |
| ssd_vgg16_512_voc |
18.721 |
19.636 |
12.004 |
54.688 |
56.174 |